Controlling Autonomous Vehicles

Introduction
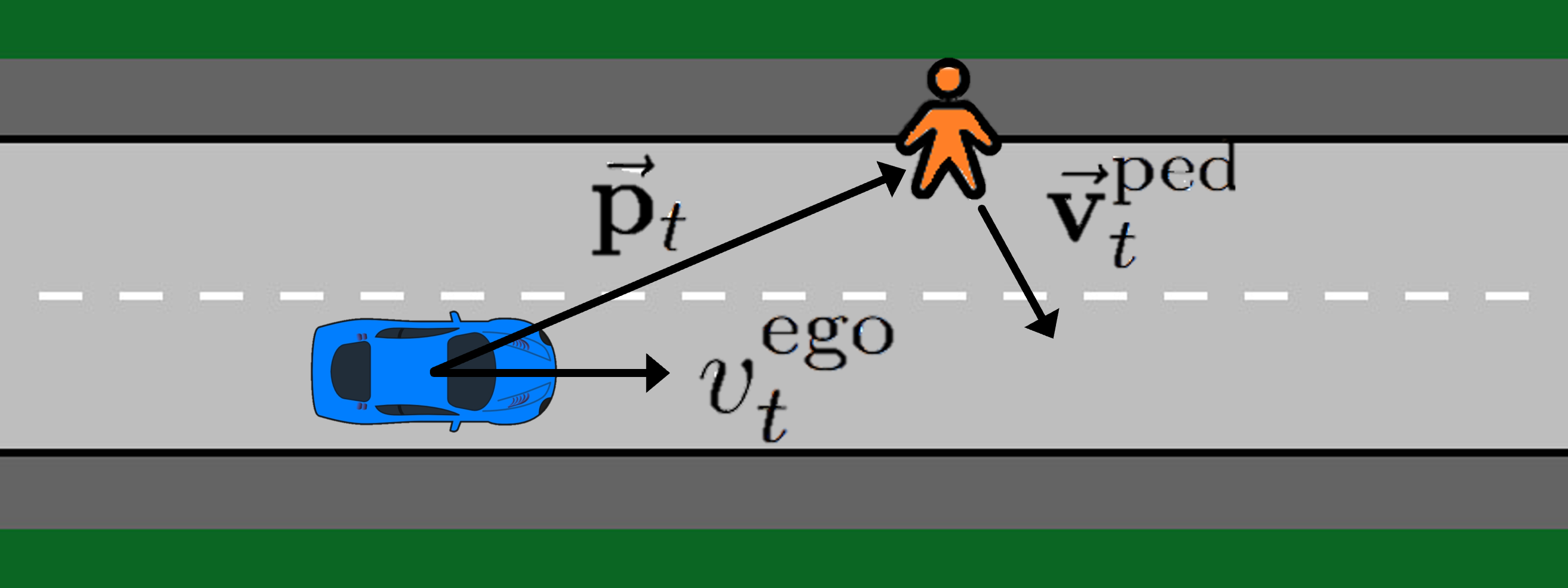
Motion control algorithms in the presence of pedestrians are critical for the development of safe and reliable Autonomous Vehicles (AVs). Traditional motion control algorithms rely on manually designed decision-making policies which neglect the mutual interactions between AVs and pedestrians. On the other hand, recent advances in Deep Reinforcement Learning allow for the automatic learning of policies without manual designs. To tackle the problem of decision-making in the presence of pedestrians, the authors introduce a framework based on Social Value Orientation and Deep Reinforcement Learning (DRL) [Crosato et al. IEEE TIV2022, Crosato et al. IEEE ICHMS2021] that is capable of generating decision-making policies with different driving styles. The policy is trained using state-of-the-art DRL algorithms in a simulated environment. A novel computationally-efficient pedestrian model that is suitable for DRL training is also introduced. We perform experiments to validate our framework and we conduct a comparative analysis of the policies obtained with two different model-free Deep Reinforcement Learning Algorithms. Simulations results show how the developed model exhibits natural driving behaviours, such as short-stopping, to facilitate the pedestrian's crossing.
The control of self-driving cars has received growing attention recently. Although existing research shows promising results in the vehicle control using video from a monocular dash camera, there has been very limited work on directly learning vehicle control from motion-based cues. Such cues are powerful features for visual representations, as they encode the per-pixel movement between two consecutive images, allowing a system to effectively map the features into the control signal. The authors propose a new framework that exploits the use of a motion-based feature known as optical flow extracted from the dash camera and demonstrates that such a feature is effective in significantly improving the accuracy of the control signals. The proposed framework in [Hu et al. IET IES2020] involves two main components. The flow predictor, as a self-supervised deep network, models the underlying scene structure from consecutive frames and generates the optical flow. The controller, as a supervised multi-task deep network, predicts both steer angle and speed. The authors demonstrate that the proposed framework using the optical flow features can effectively predict control signals from a dash camera video. Using the Cityscapes data set, the authors validate that the system prediction has errors as low as 0.0130 rad/s on steer angle and 0.0615 m/s on speed, outperforming existing research.
The control of self-driving cars has received growing attention recently. Although existing research shows promising results in the vehicle control using video from a monocular dash camera, there has been very limited work on directly learning vehicle control from motion-based cues. Such cues are powerful features for visual representations, as they encode the per-pixel movement between two consecutive images, allowing a system to effectively map the features into the control signal. The authors propose a new framework that exploits the use of a motion-based feature known as optical flow extracted from the dash camera and demonstrates that such a feature is effective in significantly improving the accuracy of the control signals. The proposed framework in [Hu et al. IET IES2020] involves two main components. The flow predictor, as a self-supervised deep network, models the underlying scene structure from consecutive frames and generates the optical flow. The controller, as a supervised multi-task deep network, predicts both steer angle and speed. The authors demonstrate that the proposed framework using the optical flow features can effectively predict control signals from a dash camera video. Using the Cityscapes data set, the authors validate that the system prediction has errors as low as 0.0130 rad/s on steer angle and 0.0615 m/s on speed, outperforming existing research.
Publications
The Team