Humam Motion Synthesis in 3D
Introduction
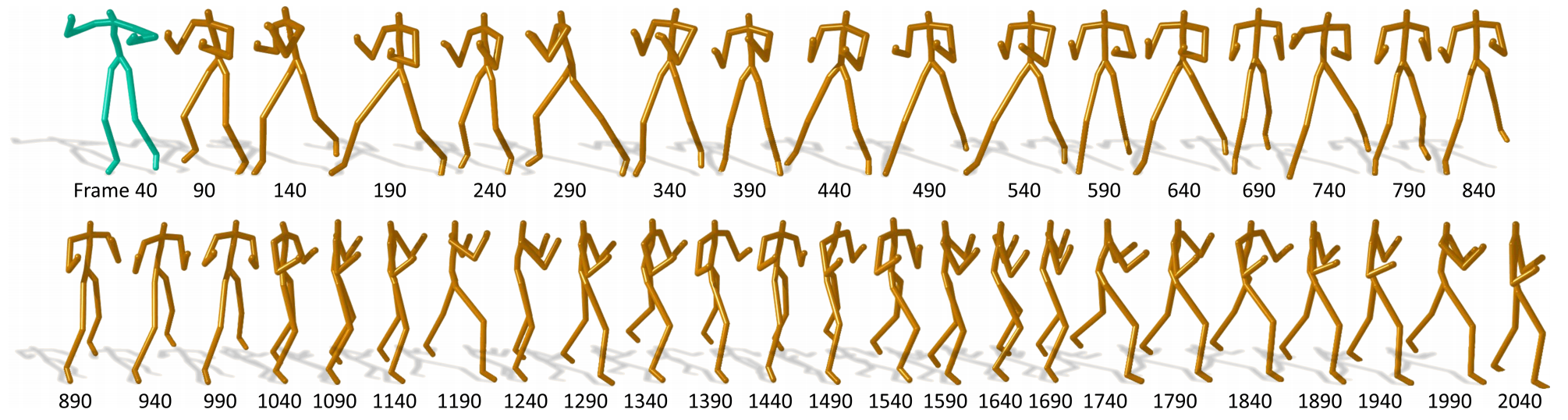
Data-driven modeling of human motions is ubiquitous in computer graphics and computer vision applications, such as synthesizing realistic motions [Shum et al. CAVW2014, Shum et al. CASA2013] or recognizing actions. Recent research has shown that such problems can be approached by learning a natural motion manifold using deep learning on a large amount data, to address the shortcomings of traditional data-driven approaches. However, previous deep learning methods can be sub-optimal for two reasons. First, the skeletal information has not been fully utilized for feature extraction. Second, motion is time-series data with strong multi-modal temporal correlations between frames. In this project, we propose a new deep network called Spatio-temporal Recurrent Neural Network (STRNN) [He et al. IEEE TVCG2021] to tackle these challenges by creating a natural motion manifold that is versatile for many applications. The network has a new spatial component for feature extraction. It is also equipped with a new batch prediction model that predicts a large number of frames at once, such that long-term temporally-based objective functions can be employed to correctly learn the motion multi-modality and variances. With our system, long-duration motions can be predicted/synthesized using an open-loop setup where the motion retains the dynamics accurately.
We further present a novel diffusion convolutional recurrent predictor for spatial and temporal movement forecasting, with multi-step random walks traversing bidirectionally along an adaptive graph to model interdependency among body joints. In the temporal domain, existing methods rely on a single forward predictor with the produced motion deflecting to the drift route, which leads to error accumulations over time. We propose to supplement the forward predictor with a forward discriminator to alleviate such motion drift in the long term under adversarial training. The solution is further enhanced by a backward predictor and a backward discriminator to effectively reduce the error, such that the system can also look into the past to improve the prediction at early frames. The two-way spatial diffusion convolutions and two-way temporal predictors together form a quadruple network (Q-DCRN) [Men et al. IEEE TCSVT2021]. Furthermore, we train our framework by modeling the velocity from observed motion dynamics instead of static poses to predict future movements that effectively reduces the discontinuity problem at early prediction.
We further present a novel diffusion convolutional recurrent predictor for spatial and temporal movement forecasting, with multi-step random walks traversing bidirectionally along an adaptive graph to model interdependency among body joints. In the temporal domain, existing methods rely on a single forward predictor with the produced motion deflecting to the drift route, which leads to error accumulations over time. We propose to supplement the forward predictor with a forward discriminator to alleviate such motion drift in the long term under adversarial training. The solution is further enhanced by a backward predictor and a backward discriminator to effectively reduce the error, such that the system can also look into the past to improve the prediction at early frames. The two-way spatial diffusion convolutions and two-way temporal predictors together form a quadruple network (Q-DCRN) [Men et al. IEEE TCSVT2021]. Furthermore, we train our framework by modeling the velocity from observed motion dynamics instead of static poses to predict future movements that effectively reduces the discontinuity problem at early prediction.
Publications
The Team